Tokenization, Stemming and Lemmatization

What is Tokenization?
Tokenization is breaking down a big chunk of text into smaller chunks. Whether it is breaking the paragraph into sentences or sentences into words or words into characters. Tokenization can be very well done using NLTK library.
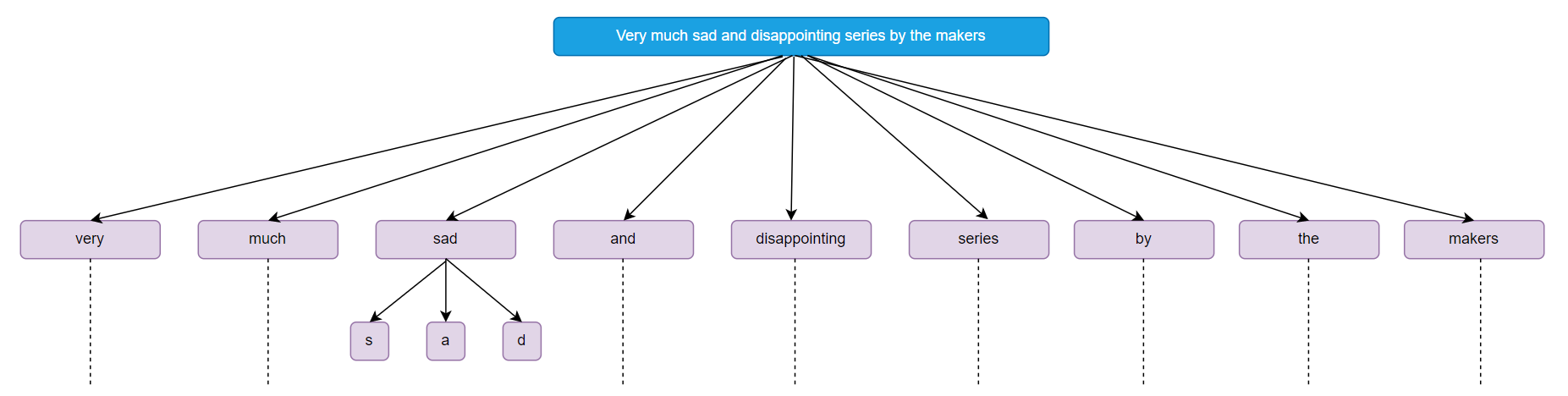 |
|---|
| Tokenization |
Code
What is Stemming?
The process of converting the words to their stem word is called as stemming. Here stem word means base word. Here the stem word has no meaning in that language.
Like chang and fina.
 |
|---|
| Stemming |
There is one problem in stemming that the words which are converted has no meaning. To resolve this issue lemmatization comes into the picture.
Code
What is Lemmatization?
It is a technique which is used to reduce words to a normalized form. This transformation uses the dictionary to map the different variants of word back to its root format.
Like final and history.
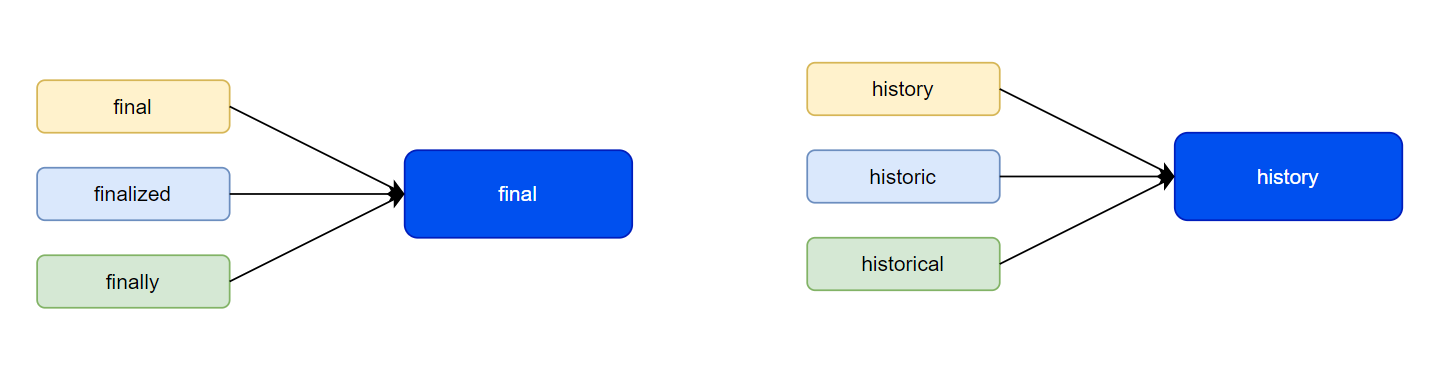 |
|---|
| Lemmatization |
It takes lot of time as it maps every word to the dictionary. Sometimes both stemming and lemmatization can be same.
Code