Regularization in Machine Learning

Need of regularization?
Have you ever faced an issue of overfitting a situation where your model performs well in you training dataset but performs poorly in you testing dataset?
If yes, then regularization can help you to come out of this issue.
Overfitting also occurs when the data is uneven or data is not preprocessed properly and our model tries to fit in this random or noisy data while training and it under performs in the testing dataset.
Algorithms like linear regression uses cost function to fit line perfectly. Goal of such algorithm is to make the cost function least as possible.
What is regularization?
The concept behind the regularization is adding one extra tuning parameter(λ) to this cost function.
It is very much important to standardize the dataset prior to applying regularization.
Regularization reduces the variance of the model without increasing the bias much.
As the value of the λ increases the value of the coefficients decreases.
But till certain point only this increase in λ is helpful as it decreases the value of the variance in the model without losing the important information in the data and after that it give rise to bias in the model which in turn leads to underfitting.
Therefore, it’s very much important that we select the value of λ carefully.
Types of regularization
- Lasso Regularization or L1 Regularization
- Ridge Regularization or L2 Regularization
In Lasso Regularization
Additional weight is absolute weight (|β|) and it is multiplied with λ as shown below.
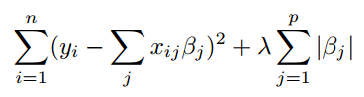 |
|---|
| L1 Regularization |
In Ridge Regularization
Additional weight is squared weight (β²) and it is multiplied with λ as shown below.
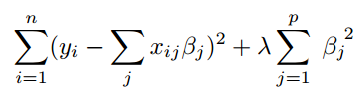 |
|---|
| L2 Regularization |